Leistungsfähige KI-Modelle auch mit wenigen eigenen Daten durch föderiertes Lernen
Viele Akteure im deutschen Gesundheitswesen erarbeiten eigene Lösungen, obwohl ihre Aufgaben häufig deckungsgleich sind. So ist der größte Teil der Prozesse einer Krankenkasse direkt aus den gesetzlichen Aufträgen an die Kassen abgeleitet. Das bedeutet fachlich sind die Prozesse identisch, doch jede Kasse setzt eigene technische Lösungen für diese Prozesse um. Und für diese Prozesse verwendet jede Krankenkasse ihr eigenes Datensilo. Diese Datensilos sind die Grundlage für potenzielle KI-Anwendungen und schränken die möglichen Use Cases ein, die eine Krankenkasse mit KI umsetzen kann.
Durch föderiertes Lernen und Kollaboration zu leistungsfähigen KI-Anwendungen
Der Entwicklung leistungsfähiger KI-Modelle stehen vor allem zwei zentrale Herausforderungen entgegen: (1) Eine zu kleine Datenmenge führt in der Regel zu schlechteren Ergebnissen, insbesondere im Bereich des maschinellen Lernens. (2) Ein Teilen von sensiblen Daten über die Kassen hinweg ist zumeist nicht gewünscht.
Förderiertes Lernen (engl. Federated Learning) umgeht diese Herausforderungen, indem der Trainingsprozess – also die besonders „Daten-intensive“ Phase – verteilt stattfindet. Dafür wird ein zentrales KI-Modell entwickelt und eine Kopie dieses Modells auf individuellen Datensätzen trainiert.
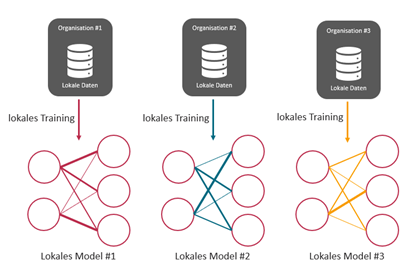
Für den Ansatz des föderierten Lernens schließen sich mehrere Kassen zusammen und trainieren mit ihren eigenen Daten jeweils ein lokales KI-Modell. Trainieren bedeutet dabei zunächst nur, dass die Parameter des Modells sich auf Basis der verwendeten Daten selbst einstellen.
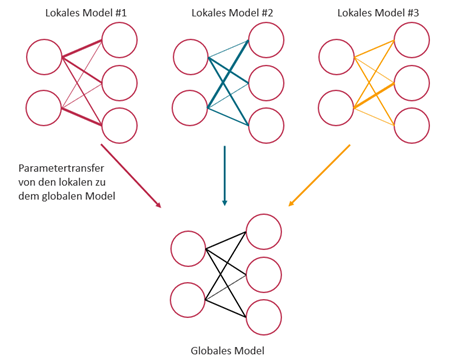
Haben die Kassen ihre einzelnen lokalen Modelle trainiert, so werden die Parameter der Modelle (also nur die Gewichtungen innerhalb der Netze und nicht die zum Training verwendeten Daten!) in einem globalen Modell zusammengeführt. Durch die entsprechende Kombination der Parameter entsteht so ein globales Modell, auch Konsensmodell genannt. Dieses globale Modell beruht implizit auf den Trainingsdaten aller lokalen Modelle und stellt einen Kompromiss aus allen lokalen Modellen dar, der eventuelle Unzulänglichkeiten einzelner lokaler Modelle, z.B. aufgrund der geringen Datenmenge mit denen diese trainiert wurden, ausgleicht.

Um auch individuell vom betriebenen Trainingsaufwand profitieren zu können, werden die Parameter des globalen Modells wieder an die lokalen Modelle der einzelnen Kassen zurückgespielt, sodass deren lokale Modelle die gleiche Mächtigkeit haben, als wären sie mit den kombinierten Daten aller teilnehmenden Kassen trainiert worden.
Je nach gewählter Modellarchitektur kann ein kontinuierlicher Lernprozess erfolgen. Dafür werden die Parameter regelmäßig gemäß oben genanntem Prozess austauscht und somit die Genauigkeit und Leistung der Modelle kontinuierlich verbessert.
Federated Learning lässt sich prinzipiell auf alle Prozesse anwenden, bei denen die Datengrundlage bei einzelnen Akteuren ggf. zu schwach für Machine-Learning-Algorithmen ist und Datenschutz eine große Rolle spielt, aber mehrere Akteure das gleiche Problem lösen müssen. Dazu zählen viele der Verwaltungsprozesse bei Krankenkassen, wie z. B. die Prüfung von Anträgen (Heil-, Hilfsmittel, Fahrkostenerstattungen, Pflegeleistungen etc.) und Rechnungen (Krankenhausabrechnungen), als auch die Vorhersage von Kündigungen.