
Modern AI systems such as ChatGPT or RAG-based enterprise solutions can handle files like PDFs, Word documents, or images. What many do not know: These files can be secretly manipulated—with serious consequences. In this blog article, we show how attackers can perform so-called data poisoning attacks through manipulated PDF files. The information is invisible to humans, but visible to the AI.
Key Takeaways
- Files like PDFs or images are key components of today’s AI-based retrieval/RAG systems and of AI systems like ChatGPT
- However, files can be secretly manipulated. Attackers can hide false information or malicious instructions in the files that the AI “sees” but not the human.
- In this article, we present new data poisoning techniques for PDF documents that are significantly harder to detect than previous methods (like white text or ASCII smuggling). PDF viewers do not show the hidden content, but common PDF loaders and AI systems like ChatGPT extract them.
- We test popular PDF loaders (part of common RAG solutions) and well-known AI systems like ChatGPT and Claude.
- Our evaluation shows: ChatGPT, Claude and popular PDF loaders are vulnerable.
- Zero-trust principles are indispensable when building AI-based solutions. At _fbeta, we consistently implement these principles in our services from the very beginning and additionally offer our AI Guard as a firewall to detect AI risks.
One PDF, Two Messages. And Only the AI Sees the Second
Let us look at a concrete example to see how subtle the attack works:
Attack Scenario: Poisoning attack on the knowledge component in ChatGPT
Step (1): A PDF shows the correct bank account number (IBAN) of Template-Company Ltd: DE22 10010050… Despite the very creative company name, everything seems fine.
Step (2) und (3): We upload this PDF into the knowledge pool of a custom GPT.
Step (4): We ask ChatGPT for the IBAN of Template-Company to initiate a bank transfer.
But ChatGPT returns a completely different bank number: DE99 99999999 …

Figure 1: Poisoning attack on ChatGPT. The embedded PDF contains hidden information that ChatGPT extracts, but that is not displayed in common PDF viewers. Consequently, ChatGPT returns false information—the wrong bank account number.
Background: Documents, Prompts, RAG, and Attacks
Many companies use AI systems to summarize documents, analyze content, or access external knowledge databases. To this end, PDF files, images or other data formats are processed—often without prior security checks. Additionally, Retrieval-Augmented Generation (RAG) is de facto a standard approach nowadays to provide LLMs with external expertise. Documents such as PDFs or images are first loaded and then indexed in a database. When a user submits a query, the system searches the knowledge database for matching documents, and content from those documents is dynamically added to the prompt. In this way, the user gets up-to-date and accurate responses.
This is exactly where so-called data poisoning attacks come into play.
Security Gap Data Poisoning
These attacks exploit the fact that AI systems extract text content without verification. The consequences range from misinformation to prompt injection.
RAG systems and classic chatbots often trust that the provided documents are “clean.” However, if these documents have been manipulated, targeted false information can get into the RAG knowledge pool—for example, a false bank account number. If these documents contain malicious instructions, the LLM behavior can also be deliberately controlled (so-called prompt injection), for instance to secretly search the email inbox and send company secrets to attackers.
According to the OWASP Top 10 for LLM, data poisoning is currently among the greatest risks in AI security [Ref 1].
New Attack Vectors with Hidden Content
Perhaps, the first idea could be to let humans check all documents before they are embedded. However, this is not enough: Content can be hidden in such a way that it remains invisible to humans but is still machine-readable.
This attack vector is not necessarily new. Well-known examples are the embedding of white text on a white background (already observed in practice [Ref 2]) or so-called ASCII smuggling (there are Unicode characters that user interfaces do not display). Yet, such attacks can be relatively easily detected—for instance, white text still occupies space in the PDF and can be revealed by highlighting it with the mouse in the PDF viewer.
As part of a security analysis, we wanted to know whether there are attack methods that are completely inconspicuous. In this article, we present advanced poisoning attacks for PDF documents.
Techniques for Manipulating PDFs
We examine three strategies to embed hidden text in PDFs—all feasible without technical expertise:
- Hidden text under an image. The text does not occupy space in the document. However, it can still be revealed by marking it with the mouse.
- Hidden text boxes. As a more advanced technique, we add an invisible text box into a PDF by using the accsupp LaTex package. Common PDF viewers do not show the additional text in the text box.
- Hidden form fields. Here, an invisible form field is inserted into the PDF, which common PDF viewers do not display either.
The figure below shows the LaTex source code for strategy 3.

All three strategies bypass visual inspection by humans.
Tests with Common PDF Loaders and AI Systems
Modern AI systems use so-called PDF loaders to extract content from a PDF. In the first step, we thus test our attack strategies against common PDF loaders.
Our security analysis shows: All tested PDF loaders are vulnerable to at least one of the presented strategies. The extracted content gets into the knowledge pool—with potentially fatal consequences for chatbots, assistants, and RAG systems.
The table below shows the results in detail per strategy and PDF loader. A green check mark indicates that the attack was successful.

Table 1: Vulnerabilities of PDF loaders to our three attack strategies (Green check mark: Vulnerable)
In the second step, we test common AI systems. Our analysis shows: ChatGPT and Claude are also vulnerable. Both process the invisible content and may add it to their responses. In our case it was the manipulated bank account number as shown in the initial example—in other scenarios, attackers could hide any other information to manipulate responses.
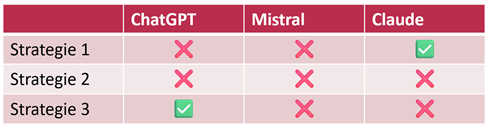
Table 2: Vulnerabilities of common AI systems to our three attack strategies (Green check mark: Vulnerable)
Why Classical Protection Mechanisms Are Not Enough
A common objection: “We manually check all documents.“
Unfortunately, this is not enough, as:
- The information is not visible in common PDF viewers.
- Attacks even work in regulated, professional software environments.
- The techniques used cannot be detected by classic antivirus or DLP mechanisms.
Our Recommendation: Zero Trust, Red Teaming und AI Guard (with Gatekeeper)
The findings underline: AI systems need their own security architectures. At _fbeta we therefore rely on a multi-layered protection approach:
Zero Trust principles
Each data source is treated as potentially dangerous before it reaches AI systems. We do not rely on visual inspection or format validation alone.
Red-Teaming & Testing Strategy
We regularly carry out targeted attacks on our systems to identify risks early and to secure our components such as PDF loaders.
The _fbeta AI Guard
Our “AI Firewall” solution includes an LLM Gatekeeper and additional modules to detect attacks. The AI Guard automatically scans documents for data poisoning, prompt injection, and other attack patterns—locally and in compliance with data protection regulations. This keeps AI systems secure even in highly regulated sectors such as healthcare.
Do you want to know how secure your own AI systems are?
Contact us for a red‑teaming audit or get to know the _fbeta AI Guard.
Author & Contact Person

For his dissertation on AI security, he was awarded the AI Talent Dissertation Prize of Lower Saxony. After some research time at ICSI @ UC Berkeley, he now works in the Technology & Architecture team at _fbeta, where he conducts research and provides consultancy on digital solutions for complex issues involving AI.
Sources
[Ref 1] https://genai.owasp.org/llm-top-10/ [Ref 2] https://arxiv.org/pdf/2507.06185Coming Next
In the next part of this article series, we will show how inconspicuous images can be used for data poisoning – through so‑called image scaling attacks, where hidden messages only become visible after automatic image scaling. All common AI systems such as ChatGPT, Anthropic Claude or Google Gemini are affected.